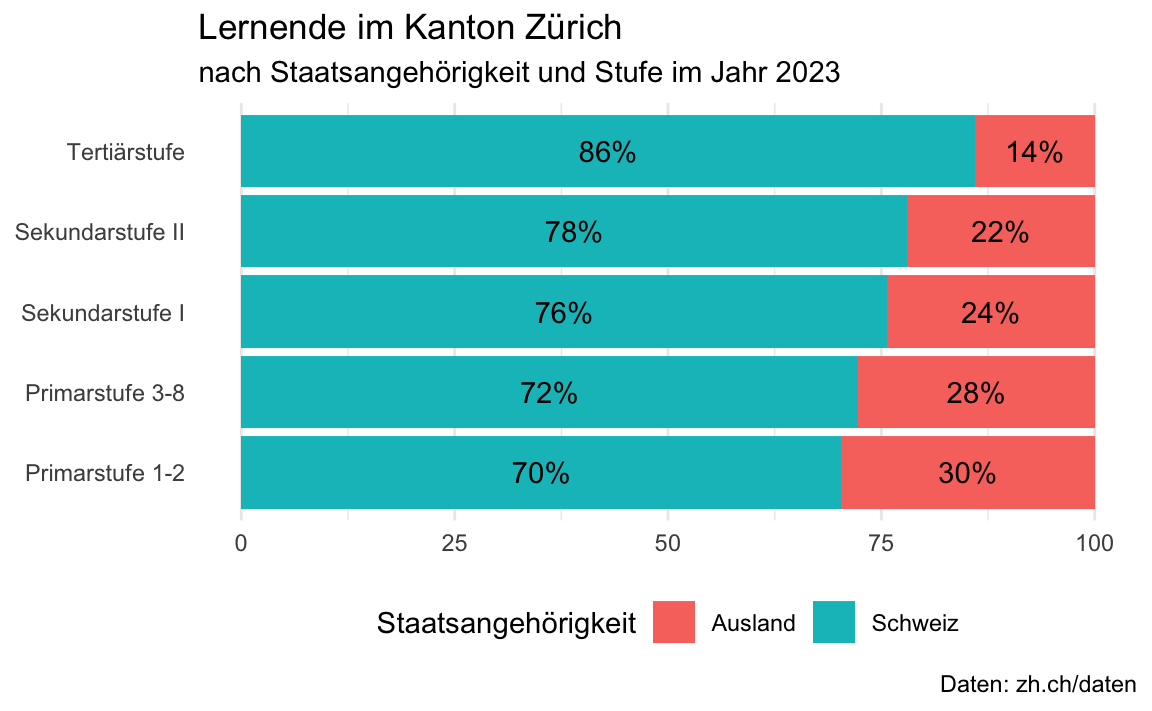
# Die Daten werden hier direkt von der URL gelesen. Bei einem Update der Daten# wird hier immer auf die aktuellste Version zugegriffen.link <-"https://www.web.statistik.zh.ch/ogd/data/bista/ZH_Uebersicht_alle_Lernende.csv"# Hier wird nun das Objekt "link" genutzt um die CSV zu lesenlernende_in <-read_csv(file = link)
Rows: 2972 Columns: 10
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (7): Kanton, Stufe, Schultyp, Geschlecht, Staatsangehoerigkeit, Traeger...
dbl (2): Jahr, Anzahl
date (1): Stand
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 36 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): titel, lernziele
dbl (1): modul
dttm (1): datum
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Die Lernenden können die Bedeutung von Vektoren mit Bezug auf einen Dataframe erläutern.
Die Lernenden können drei verschiedene Methoden anwenden um auf einen Vektor in einem dataframe zuzugreifen.
Die Lernenden können die vier wichtigsten atomaren Vektortypen in R auflisten.
Die Lernenden können einen for loop verwenden, um durch die Elemente eines Vektors in einem Dataframe zu iterieren und spezifische Operationen auf jedes Element anzuwenden.
Rows: 5 Columns: 12
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): location, day_of_collection
dbl (10): objid, bin_id, bin_id_2, non_recyclables_ Kg, pet_Kg, metal_conten...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 5 Columns: 12
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): location, day_of_collection
dbl (10): objid, bin_id, bin_id_2, non_recyclables_ Kg, pet_Kg, metal_conten...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 22 Columns: 15
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (14): Date Started, age, job, residence_situation, residence_type, locat...
dbl (1): residence_distance
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Warning: There was 1 warning in `summarise()`.
ℹ In argument: `mean_price_glass = mean(price_glass)`.
Caused by warning in `mean.default()`:
! argument is not numeric or logical: returning NA
Warning: There was 1 warning in `summarise()`.
ℹ In argument: `mean_price_glass = mean(price_glass, na.rm = TRUE)`.
Caused by warning in `mean.default()`:
! argument is not numeric or logical: returning NA
Warning: There was 1 warning in `summarise()`.
ℹ In argument: `mean_price_glass = mean(price_glass_new, na.rm = TRUE)`.
Caused by warning in `mean.default()`:
! argument is not numeric or logical: returning NA
# A tibble: 1 × 1
mean_price_glass
<dbl>
1 NA
Respektiere deine Daten Typen!
Den Durchschnitt von einem Vektor mit Typ “character” zu berechnen ist nicht möglich.
Ich bin dran: Vektoren und Iteration mit for-Schleifen
Zurücklehnen und Fragen stellen!
countdown(minutes =40)
40:00
Pause machen
Bitte steh auf und beweg dich.
countdown(minutes =10)
10:00
Ihr seid dran: 02-iteration-ihr.qmd
Öffne posit.cloud in deinem Browser (verwende dein Lesezeichen).
Öffne den rstatszh-k011 Arbeitsbereich (Workspace) für den Kurs.
Klicke auf Start neben md-06-uebungen.
Suche im Dateimanager im Fenster unten rechts die Datei 02-iteration-ihr.qmd und klicke darauf, um sie im Fenster oben links zu öffnen.
Folge den Anweisungen in der Datei.
countdown(40)
40:00
Zeitpuffer: Modul 6 Uebungen
Kann ich noch etwas zu den Übungen in 02-iteration-ihr.qmd sagen?
countdown(5)
05:00
Pause machen
Bitte steh auf und beweg dich.
countdown(minutes =5)
05:00
Sensitive Daten und GitHub
schützenswerte Daten dürfen nicht auf GitHub
schützenswerte Daten:
verletzen die Privatsphäre (z.B. Einzeldaten)
sind sicherheitskritisch (z.B. Passwörter)
unterliegen Drittrechten (z.B. Copyrights)
Lösung: .gitignore
Dateien und Verzeichnisse in .gitignore eintragen
werden nicht auf GitHub hochgeladen
Daten teilen
Damit eine Analyse reproduzierbar ist, müssen die Daten für andere zugänglich sein. Die Dateien können auf anderen Wegen geteilt werden, z.B. per E-Mail, USB-Stick, Cloud-Dienst, etc.
Informationssicherheit
Folgender Dateipfad enthält Informationen zum Dateisystem und sollte nicht auf GitHub hochgeladen werden:
Ein guter Weg dies zu vermeiden ist die Verwendung von relativen Pfaden in Kombination mit der here() Funktion aus dem gleichnamigen R-Paket here. Im RStudio Project / GitHub Repository mit dem Namen projekt-umfrage:
read_csv(here::here("daten/umfrage_daten.csv"))
Wir sind dran: 03-gitignore-wir.qmd & docs/04-dateipfade.qmd
Öffne posit.cloud in deinem Browser (verwende dein Lesezeichen).
Öffne den rstatszh-k011 Arbeitsbereich (Workspace) für den Kurs.
Klicke auf Continue neben md-06-uebungen.
Suche im Dateimanager im Fenster unten rechts die Datei 03-gitignore-wir.qmd und klicke darauf, um sie im Fenster oben links zu öffnen.